Simplex algorithm
In mathematical optimization theory, the simplex algorithm, created by the American mathematician George Dantzig in 1947, is a popular algorithm for numerically solving linear programming problems. The journal Computing in Science and Engineering listed it as one of the top 10 algorithms of the century.[1]
The method uses the concept of a simplex, which is a polytope of N + 1 vertices in N dimensions: a line segment in one dimension, a triangle in two dimensions, a tetrahedron in three-dimensional space and so forth.
Contents |
Overview

Consider a linear programming problem,
- maximize
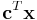
- subject to
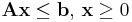
with 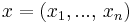 the variables of the problem,
the variables of the problem, 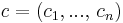 a vector representing the linear form to optimize, A a rectangular p,n matrix and
a vector representing the linear form to optimize, A a rectangular p,n matrix and 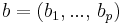 the linear constraints.
the linear constraints.
In geometric terms, each inequality specifies a half-space in n-dimensional Euclidean space, and their intersection is the set of all feasible values the variables can take. The region is convex and either empty, unbounded, or a polytope.
The set of points where the objective function obtains a given value v is defined by the hyperplane 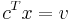 . We are looking for the largest v such that the hyperplane still intersects the feasible region. As v increases, the hyperplane translates in the direction of the vector c. Intuitively, and indeed it can be shown by convexity, the last hyperplane to intersect the feasible region will either just graze a vertex of the polytope, or a whole edge or face. In the latter two cases, it is still the case that the endpoints of the edge or face will achieve the optimum value. Thus, the optimum value will always be achieved on (at least) one of the vertices of the polytope.
. We are looking for the largest v such that the hyperplane still intersects the feasible region. As v increases, the hyperplane translates in the direction of the vector c. Intuitively, and indeed it can be shown by convexity, the last hyperplane to intersect the feasible region will either just graze a vertex of the polytope, or a whole edge or face. In the latter two cases, it is still the case that the endpoints of the edge or face will achieve the optimum value. Thus, the optimum value will always be achieved on (at least) one of the vertices of the polytope.
The simplex algorithm applies this insight by walking along edges of the (possibly unbounded) polytope to vertices with higher objective function value. When a local maximum is reached, by convexity it is also the global maximum and the algorithm terminates. It also finishes when an unbounded edge is visited, concluding that the problem has no solution. The algorithm always terminates because the number of vertices in the polytope is finite; moreover since we jump between vertices always in the same direction (that of the objective function), we hope that the number of vertices visited will be small. Usually there are more than one adjacent vertices which improve the objective function, so a pivot rule must be specified to determine which vertex to pick. The selection of this rule has a great impact on the runtime of the algorithm.
In 1972, Klee and Minty[2] gave an example of a linear programming problem in which the polytope P is a distortion of an n-dimensional cube. They showed that the simplex method as formulated by Dantzig visits all 2n vertices before arriving at the optimal vertex. This shows that the worst-case complexity of the algorithm is exponential time. Since then, for almost every deterministic rule, it has been shown that there is a family of simplices on which it performs badly. It is an open question if there is a pivot rule with polynomial time, or even sub-exponential worst-case complexity.
Nevertheless, the simplex method is remarkably efficient in practice. It has been known since the 1970s that it has polynomial-time average-case complexity under various distributions. These results on "random" matrices still didn't quite capture the desired intuition that the method works well on "typical" matrices. In 2001 Spielman and Teng introduced the notion of smoothed complexity to provide a more realistic analysis of the performance of algorithms.[3]
Other algorithms for solving linear programming problems are described in the linear programming article.
Algorithm
The simplex algorithm requires the linear programming problem to be in augmented form, so that the inequalities are replaced by equalities. The problem can then be written as follows in matrix form:
- Maximize Z in:
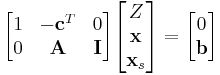
where 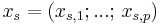 are the introduced slack variables from the augmentation process, ie the non-negative distances between the point and the hyperplanes representing the linear constraints A.
are the introduced slack variables from the augmentation process, ie the non-negative distances between the point and the hyperplanes representing the linear constraints A.
By definition, the vertices of the feasible region are each at the intersection of n hyperplanes (either from A or 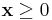 ). This corresponds to n zeros in the n+p variables of (x, xs). Thus 2 feasible vertices are adjacent when they share n-1 zeros in the variables of (x, xs). This is the interest of the augmented form notations : vertices and jumps along edges of the polytope are easy to write.
). This corresponds to n zeros in the n+p variables of (x, xs). Thus 2 feasible vertices are adjacent when they share n-1 zeros in the variables of (x, xs). This is the interest of the augmented form notations : vertices and jumps along edges of the polytope are easy to write.
The simplex algorithm goes as follows :
- Start off by finding a feasible vertex. It will have at least n zeros in the variables of (x, xs), that will be called the n current non-basic variables. (Finding a feasible vertex is a non-trivial problem if initial LP is not standard form.)
- Write Z as an affine function of the n current non-basic variables. This is done by transvections to move the non-zero coefficients in the first line of the matrix above.
- Now we want to jump to an adjacent feasible vertex to increase Z's value. That means increasing the value of one of the non-basic variables, while keeping all n-1 others to zero. Among the n candidates in the adjacent feasible vertices, we choose that of greatest positive increase rate in Z, also called direction of highest gradient.
- The changing non-basic variable is therefore easily identified as the one with maximum positive coefficient in Z.
- If there are already no more positive coefficients in Z affine expression, then the solution vertex has been found and the algorithm terminates.
- Next we need to compute the coordinates of the new vertex we jump to. That vertex will have one of the p current basic variables set to 0, that variable must be found among the p candidates. By convexity of the feasible polytope, the correct basic variable is the one that, when set to 0, minimizes the change in the moving non-basic variable. This is easily found by computing p ratios of coefficients and taking the lowest ratio. That new variable replaces the moving one in the n non-basic variables and the algorithm loops back to writing Z as a function of these.
Example
Rewrite 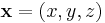 and
and 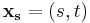 :
:
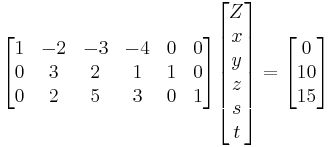
x=0 is clearly a feasible vertex so we start off with it : the 3 current non-basic variables are x, y and z. Luckily Z is already expressed as an affine function of x,y,z so no transvections need to be done at this step. Here Z 's greatest coefficient is -4, so the direction with highest gradient is z. We then need to compute the coordinates of the vertex we jump to increasing z. That will result in setting either s or t to 0 and the correct one must be found. For s, the change in z equals 10/1=10 ; for t it is 15/3=5. t is the correct one because it minimizes that change. The new vertex is thus x=y=t=0. Rewrite Z as an affine function of these new non-basic variables :
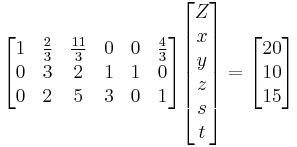
Now all coefficients on the first row of the matrix have become nonnegative. That means Z cannot be improved by increasing any of the current non-basic variables. The algorithm terminates and the solution is the vertex x=y=t=0. On that vertex Z=20 and this is its maximum value. Usually the coordinates of the solution vertex are needed in the standard variables x, y, z ; so a little substitution yields x=0, y=0 and z=5.
Implementation
The tableau form used above to describe the algorithm lends itself to an immediate implementation in which the tableau is maintained as a rectangular (m+1)-by-(m+n+1) array. It is straightforward to avoid storing the m explicit columns of the identity matrix that will occur within the tableau by virtue of B being a subset of the columns of ![[\mathbf{A} \, \mathbf{I}]](/2010-wikipedia_en_wp1-0.8_orig_2010-12/I/e116640d8ef1006dbf0663f62335e7ac.png) . This implementation is referred to as the standard simplex method. The storage and computation overhead are such that the standard simplex method is a prohibitively expensive approach to solving large linear programming problems.
. This implementation is referred to as the standard simplex method. The storage and computation overhead are such that the standard simplex method is a prohibitively expensive approach to solving large linear programming problems.
In each simplex iteration, the only data required are the first row of the tableau, the (pivotal) column of the tableau corresponding to the entering variable and the right-hand-side. The latter can be updated using the pivotal column and the first row of the tableau can be updated using the (pivotal) row corresponding to the leaving variable. Both the pivotal column and pivotal row may be computed directly using the solutions of linear systems of equations involving the matrix B and a matrix-vector product using A. These observations motivate the revised simplex method, for which implementations are distinguished by their invertible representation of B.
In large linear programming problems A is typically a sparse matrix and, when the resulting sparsity of B is exploited when maintaining its invertible representation, the revised simplex method is a vastly more efficient solution procedure than the standard simplex method. Commercial simplex solvers are based on the primal (or dual) revised simplex method.
See also
- Nelder-Mead method
- Fourier-Motzkin elimination
- Bland's anti-cycling rule
- Karmarkar's algorithm
References
- ↑ Computing in Science and Engineering, volume 2, no. 1, 2000
- ↑ Greenberg, cites: V. Klee and G.J. Minty. "How Good is the Simplex Algorithm?" In O. Shisha, editor, Inequalities, III, pages 159–175. Academic Press, New York, NY, 1972
- ↑ Spielman, Daniel; Teng, Shang-Hua (2001), "Smoothed analysis of algorithms: why the simplex algorithm usually takes polynomial time", Proceedings of the Thirty-Third Annual ACM Symposium on Theory of Computing, ACM, pp. 296–305, doi:10.1145/380752.380813, arXiv:cs/0111050, ISBN 978-1-58113-349-3
Further reading
- Dmitris Alevras and Manfred W. Padberg, Linear Optimization and Extensions: Problems and Extensions, Universitext, Springer-Verlag, 2001. (Problems from Padberg with solutions.)
- J. E. Beasley, editor. Advances in Linear and Integer Programing. Oxford Science, 1996. (Collection of surveys)
- R.G. Bland, New finite pivoting rules for the simplex method, Math. Oper. Res. 2 (1977) 103–107.
- Karl-Heinz Borgwardt, The Simplex Algorithm: A Probabilistic Analysis, Algorithms and Combinatorics, Volume 1, Springer-Verlag, 1987. (Average behavior on random problems)
- Richard W. Cottle, ed. The Basic George B. Dantzig. Stanford Business Books, Stanford University Press, Stanford, California, 2003. (Selected papers by George B. Dantzig)
- George B. Dantzig and Mukund N. Thapa. 1997. Linear programming 1: Introduction. Springer-Verlag.
- George B. Dantzig and Mukund N. Thapa. 2003. Linear Programming 2: Theory and Extensions. Springer-Verlag.
- Komei Fukuda and Tamás Terlaky, Criss-cross methods: A fresh view on pivot algorithms. (1997) Mathematical Programming Series B, Vol 79, Nos. 1--3, 369--395. (Invited survey, from the International Symposium on Mathematical Programming.)
- Kattta G. Murty, Linear Programming, Wiley, 1983. (comprehensive textbook and reference, through ellipsiodal algorithm of Khachiyan)
- Evar D. Nering and Albert W. Tucker, 1993, Linear Programs and Related Problems, Academic Press. (elementary)
- M. Padberg, Linear Optimization and Extensions, Second Edition, Springer-Verlag, 1999. (carefully written account of primal and dual simplex algorithms and projective algorithms, with an introduction to integer linear programming --- featuring the traveling salesman problem for Odysseus.)
- Christos H. Papadimitriou and Kenneth Steiglitz, Combinatorial Optimization: Algorithms and Complexity, Corrected republication with a new preface, Dover. (computer science)
- Alexander Schrijver, Theory of Linear and Integer Programming. John Wiley & sons, 1998, ISBN 0-471-98232-6 (mathematical)
- Michael J. Todd (February 2002). "The many facets of linear programming". Mathematical Programming 91 (3). (Invited survey, from the International Symposium on Mathematical Programming.)
- Greenberg, Harvey J., Klee-Minty Polytope Shows Exponential Time Complexity of Simplex Method University of Colorado at Denver (1997) PDF download
- Frederick S. Hillier and Gerald J. Lieberman: Introduction to Operations Research, 8th edition. McGraw-Hill. ISBN 0-07-123828-X
- Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. Introduction to Algorithms, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Section 29.3: The simplex algorithm, pp.790–804.
- Hamdy A. Taha: Operations Research: An Introduction, 8th ed., Prentice Hall, 2007. ISBN 0-13-188923-0
- Richard B. Darst: Introduction to Linear Programming: Applications and Extensions
- Press, William H., et. al.: Numerical Recipes in C, Second Edition, Cambridge University Press, ISBN 0-521-43108-5. Section 10.8: Linear Programming and the Simplex Method, pp.430-444. (A different tableau format, for which the use of the word pivot is quite intuitive. Computer code in C.)
External links
- An Introduction to Linear Programming and the Simplex Algorithm by Spyros Reveliotis of the Georgia Institute of Technology.
- LP-Explorer A Java-based tool which, for problems in two variables, relates the algebraic and geometric views of the tableau simplex method. Also illustrates the sensitivity of the solution to changes in the right-hand-side.
- Java-based interactive simplex tool hosted by Argonne National Laboratory.
- Tutorial for The Simplex Method by Stefan Waner, hofstra.edu. Interactive worked example.
- A simple example - step by step by Mazoo's Learning Blog.
- simplex me - the simple simplex solver (Solve your linear problems with simplex algorithm online - multilanguage, PDF Export)
- Simplex Method A good tutorial for Simplex Method with examples (also two-phase and M-method).
- PHPSimplex Other good tutorial for Simplex Method with the Two-Phase Simplex and Graphical methods, examples, and a tool to solve Simplex problems online.
- Simplex Method Tool Quick-loading JavaScript-based web page that solves Simplex problems
- LiSimplex Solver LiSimplex - The OpenSource Java Simplex Solver
- Complex An Open Source Application for Linear Programming that resolves a giving model and shows step to step the iterations of the simplex method. (Penalization Method and Two Phases Method).
|
||||||||